Python多线程下载网络图片
计算密集型和 IO 密集型
面对不同的任务,计算机所调用的资源是不一样的,受限制的情况也是不同的,我们可以分成下面几类:
- CPU Bound:计算机在处理大量的计算任务时,收到CPU的限制会很大,比如计算开根号,浮点数运算,阶乘,小型矩阵计算等等。
- I/O Bound:计算机在对硬盘进行读写操作时,会受到磁盘读写速度的限制,当然网络IO也同样可以被归为此类。
除了这两个,还有Memory Bound和Cache Bound,不再一一介绍。
编程时,面对不同的任务,有不同的限制,所以要采取不同的策略。
比如,计算数据时,我们面对的是CPU运算速度的限制,现在电脑都是多核心,一个不够,上两个。
如果是网络请求,磁盘读写,则可以使用多线程的形式,在等待IO时候,进行其他的任务。
使用requests下载图片
import requests
def download_image(image_url, path_name):
r = requests.get(image_url)
with open(f'./pictures/{path_name}.png', 'wb') as image_file:
image_file.write(r.content)
print(f'image_{path_name} is downloaded!')
逻辑很简单,获取指定的图片url,下载到pictures文件夹下。
单线程下载
下载网络图片属于IO密集型任务,单线程下载,很慢很慢,其中一大部分都在等待网络请求的延迟,就好比做菜,只有单个煤气灶,菜只能一个一个烧,等上一个结束了,下一个才能开始。
代码:
import requests
import time
import threading
import concurrent.futures
# unsplash是一个壁纸网站,这是作为示例的一些图片URL
image_urls = [
'https://images.unsplash.com/photo-1562887284-8ba6b7c90fd8?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=2000&q=8',
'https://images.unsplash.com/photo-1586971934493-d6829d89393c?ixlib=rb-1.2.1&auto=format&fit=crop&w=675&q=80',
'https://images.unsplash.com/photo-1586897456860-f5b8454e69d4?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=334&q=80',
'https://images.unsplash.com/photo-1586912597722-f4f14ed28572?ixlib=rb-1.2.1&auto=format&fit=crop&w=334&q=80',
'https://images.unsplash.com/photo-1586902279529-18f29e8bc12c?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=1050&q=80',
'https://images.unsplash.com/photo-1586919821724-78540b8f04db?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=1050&q=80',
'https://images.unsplash.com/photo-1586917049301-c804fb01f961?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=333&q=80',
'https://images.unsplash.com/photo-1586920257793-de7b5c89036b?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=334&q=80',
'https://images.unsplash.com/photo-1586880344885-dd80bdec31ce?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=334&q=80',
'https://images.unsplash.com/photo-1586915039812-277dcd0a01ed?ixlib=rb-1.2.1&auto=format&fit=crop&w=700&q=80',
'https://images.unsplash.com/photo-1586901140882-2788c4eb9056?ixlib=rb-1.2.1&auto=format&fit=crop&w=1067&q=80',
'https://images.unsplash.com/photo-1558980664-3a031cf67ea8?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=1050&q=80',
'https://images.unsplash.com/photo-1586909165450-c601cd788f3c?ixlib=rb-1.2.1&auto=format&fit=crop&w=323&q=80',
'https://images.unsplash.com/photo-1586951900615-7439de3e65cf?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=334&q=80',
]
def download_image(image_url, path_name):
r = requests.get(image_url)
with open(f'./pictures/{path_name}.png', 'wb') as image_file:
image_file.write(r.content)
print(f'image_{path_name} is downloaded!')
def main():
# 计时开始
start_time = time.time()
# 根据image_urls列表的url一个一个去下载
for index, image_url in enumerate(image_urls):
download_image(image_url, str(index))
# 计时结束
print(f'It spends {time.time() - start_time} seconds')
if __name__ == '__main__':
main()
下载速度:
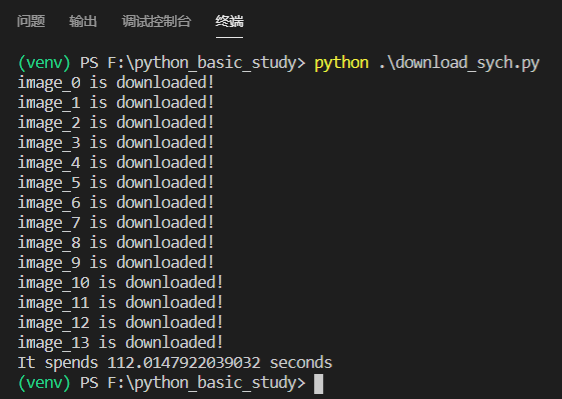
总共花了112秒。。。相当慢,只有等上一张图片下载完,才能再发起下一个请求下载新的图片。
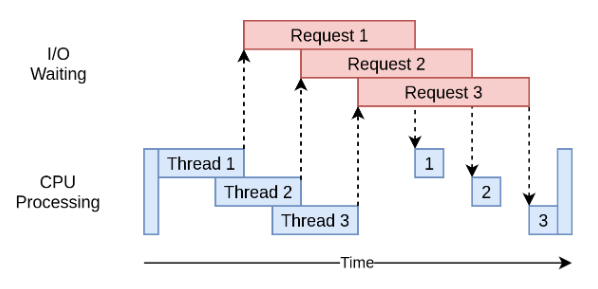
多线程下载
多线程下载,就是开多个thread去执行任务,线程1在等待资源的时候,线程2可以
发起请求,同样的,线程2发起请求以后也会进入等待,线程3就可以发起请求…
放个图:
代码:
def main():
start_time = time.time()
threads = []
for index, image_url in enumerate(image_urls):
t = threading.Thread(target=download_image, args=(image_url, str(index)))
t.start()
threads.append(t)
for t in threads:
t.join()
print(f'It spends {time.time() - start_time} seconds')
只要把上面单线程的main函数改一下,就可以了,这里用的是传统方法,用列表threads来保存由threading.Thread创建的线程,然后遍历join()。
下载速度:
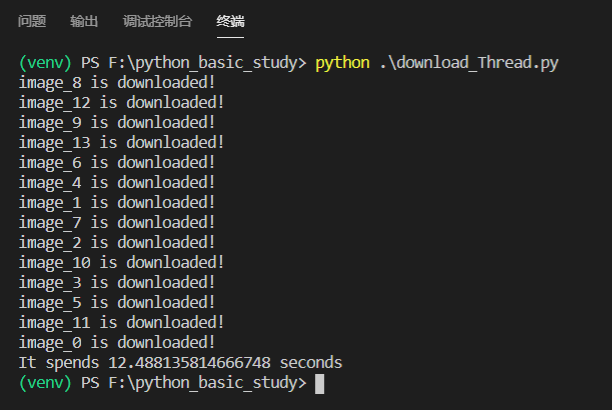
十倍的速度有木有!超级快。
当然,concurrent.futures提供了更加优雅的写法,那就是ThreadPoolExecutor,它是python提供给我们的线程池模块。
def main():
start_time = time.time()
with concurrent.futures.ThreadPoolExecutor() as executor:
for index, image_url in enumerate(image_urls):
executor.submit(download_image, image_url, index)
print(f'It spends {time.time() - start_time} seconds')
代码非常少,仅仅是创建一个线程池,然后把对应的函数放到submit当中。
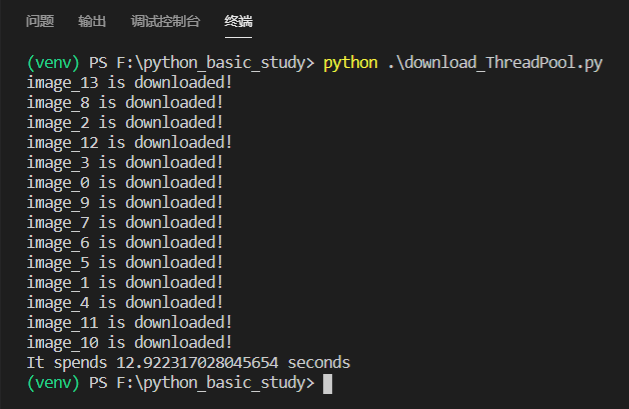
下载速度:
小结
python的多线程并不是运行在多核上的,由于GIL(Global Interpreter Lock,全局解释器锁)的存在,所以在每个时刻,单核CPU,仅有一个线程在运行,可以说是并发而不是并行(并发和并行在宏观角度上都是在同一个时间段同时完成多个任务,但从微观角度来讲,同一时刻下,并发只是处理单个任务,并行才是真正运行在多核上,同时完成。)
对于CPU密集型的任务而言,pyhton的多线程并没什么用,反而比单线程慢,由于创建线程,切换线程需要额外的开销,而同一时刻运行的又只有一个线程,所以如同鸡肋。应对CPU密集型的任务,可以采用MultiProcess,多进程来进行处理,这样每个进程都有自己GIL,互不干扰,达到并行的效果。
对于IO密集型任务而言(文件处理,网络爬虫),单线程有时会进行IO等待,造成不必要的时间浪费,开启多线程后,可以自动切换线程,节省时间。